
SQL数据库查询经常包括相同操作的重复。例如,在一个表中找到一个对应于某个人的条目,可能需要拉出这个人的名字的所有条目和这个人的姓氏的所有条目,并计算它们的交叉点。如果名和姓的搜索需要查询同一个数据库表两次,这就是一种冗余,会增加检索时间。
在我们上周在IEEE国际数据工程会议(ICDE)上发表的一篇论文中,我们描述了一种重写复杂SQL查询的方法,以消除这种冗余。有时,这涉及到检索一个超集的条目,然后根据额外的标准将它们筛选出来。但一般来说,在检索后进行一点额外的计算比对同一个表进行多次查询更有效率。
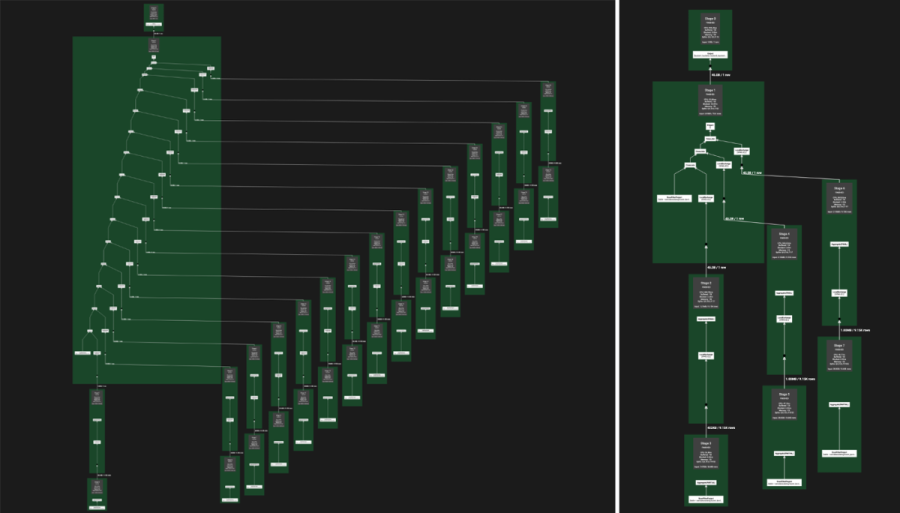
查询计划是执行一个SQL查询所需的步骤序列。左图是描述TPC-DS数据集中一个复杂查询的标准查询计划。右图是由亚马逊研究人员的新改写规则产生的更简单的查询计划。
在TPC-DS基准数据库的实验中,有3TB的数据,我们的技术将99个查询的总体执行时间比基准线提高了14%。当仅限于那些被我们的重写规则直接转化的查询时,我们观察到性能提高了60%,一些查询的执行速度提高了6倍以上。
重写查询
查询计划是一连串的步骤,例如用于执行查询的数据扫描和聚合。查询计划优化是指从大量可能的备选方案中选择最有效的查询计划的过程。

相关内容
亚马逊Redshift。十年来的不断重塑 (https://www.amazon.science/latest-news/amazon-redshift-ten-years-of-continuous-reinvention)
亚马逊Redshift研究论文的两位作者将在领先的国际数据库研究者论坛上发表,他们反思了第一个PB级的云数据仓库自十年前宣布以来取得了多大的进展。
我们工作的重点是识别在重叠数据上计算的子查询,并将它们融合到一个带有补偿动作(检索后计算)的单一计算中,以重建原始结果。它不要求子查询在语法上相同或产生相同的输出。
考虑下面的查询作为一个例子。
WITH cte as (...complex_subquery...)
SELECT customer_id FROM cte WHERE fname = 'John'
UNION ALL
SELECT customer_id FROM cte WHERE lname = 'Smith'
该查询在FROM子句中两次使用cte块。这是不理想的,特别是当重复的计算是昂贵的。我们的技术可以识别这种模式并重写它们。例如,上述查询变成
WITH cte as (…complex_subquery…)
SELECT customer_id FROM cte, (VALUES (1), (2)) T(tag)
WHERE (fname = ‘John’ AND tag=1)
OR (lname = ‘Smith’ AND tag=2)
尽管常见的表达式并不完全相同(在WHERE子句中有不同的过滤条件),但我们能够将查询重写成一个片段,生成所需行和列的超集,并通过补偿动作处理差异。
注意,一般来说,并不是所有带有重复表达式的查询都可以通过消除重复的工作来重写。然而,除了这里显示的查询模式外,还有几种情况适用于重写的情况。
重写规则的构建模块

相关内容
如何降低数据库查询的通信开销达97%(https://www.amazon.science/blog/how-to-reduce-communication-overhead-for-database-queries-by-up-to-97)
亚马逊研究人员描述了在服务器间分配数据库表的新方法。
这里是我们新的查询计划优化规则中将要使用的基元。具体来说,我们定义了一个函数Fuse,它接收两个输入计划并返回⊥(当融合不可能时)或4元组融合结果。如果Fuse(P1, P2) = (P, M, L, R), 那么
- P是融合后的计划。P的模式包括P1中的所有输出列,也可以选择P2中的额外输出列。
- M是一个从P2的输出列到P的输出列的映射。
- L和R是定义在P的输出列上的两个过滤条件,分别用于恢复P1和P2。
从语义上讲,我们可以对P1和P2进行如下重建。
P1 = ProjectoutCols(P1)(FilterL(P))
P2 = ProjectM(outCols(P2))(FilterR(P))
其中outCols(P)表示计划P的输出列。
Fuse是一个递归函数,可以处理不同的操作,如表扫描、过滤、投影、连接、聚合和不同的聚合。
优化规则
我们引入了一些优化规则,根据上面定义的基元重写查询计划。如果我们发现足够普遍的模式,并且有语义上的等效表示,就可以添加新的规则。

相关内容
亚马逊EBS在规模上解决了CAP定理的难题(https://www.amazon.science/blog/amazon-ebs-addresses-the-challenge-of-the-cap-theorem-at-scale)
优化配置数据的放置,确保其在 “网络分区 “期间的可用性和一致性。
- GroupByJoinToWindow
这个规则转变了一个常见的模式,在这个模式中,一个表达式被聚合,并连接回自己,以获得聚合行的额外信息。直观地说,它是一种计算,用在列的子集上计算的聚合来扩展一个输入关系。窗口函数以这种方式操作,可以用来重写原始模式。
JoinOnKeys
这个规则解决了一个常见的模式,即类似的子查询,返回相同数据的不同视图,被自我连接在一起。由于键的存在,左边的每一行最多只能与右边的一行匹配。因此,我们要扩展每一条与两边的列相匹配的行。
UnionAllOnJoin
这个规则处理的情况是,客户将两个计算的结果结合在一起,这些计算在整体上非常相似,但在一个表上有所不同(例如,他们将一些应用于不同事实表的分析性见解结合在一起)。
UnionAll
这个规则对应于上一节中的例子查询。这是一个常见的模式,客户使用它来计算一个共同的表达式,然后用不同的投影将结果中非必要的不相干的子集联合起来。
文中提出的工作已经在生产中使用。值得注意的是,虽然Athena从中受益,但同样的技术也适用于其他数据库系统,因为它们不需要实现新的运算符或执行模型。
我们很高兴地看到,作为结果,我们的客户正在更快地运行他们的查询,并且由于扫描的数据更少,降低了他们的账单。
文章来源:https://www.amazon.science/blog/speeding-database-queries-by-rewriting-redundancies